今日進度8/14:修正Flex Message、修正流程圖
今天花了很多時間在修Flex Message,也用了copilot但還是不行,決定先來根據現在的基礎原型作流程圖的修正!
(最一開始的流程圖是沒有語音服務,而且沒有計算BMI,現在都有了!灑花)
修正流程圖後如下:
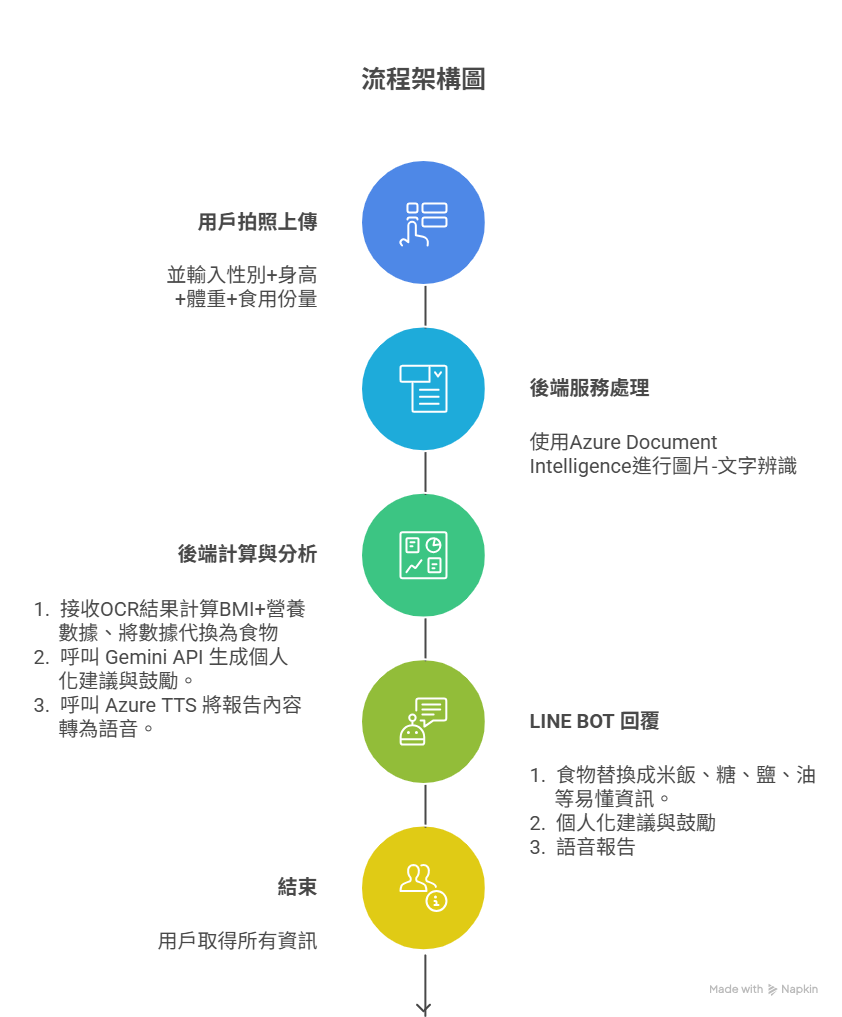
系統架構細節說明
「每拍呷」的核心是一套以 LINE Bot 為介面,並由後端雲端服務串接多個 AI 功能的整合性系統。整個流程旨在實現從「圖片輸入」到「語音報告輸出」的自動化、智慧化處理。
使用者介面 (LINE Bot):LINE Bot 作為整個服務的入口,提供最直覺、最無障礙的使用體驗。用戶無需下載額外的應用程式,只需在 LINE 上傳圖片,就能立即與後端系統互動。此外,後端產生的報告與語音,也會透過 LINE Bot 即時傳送給用戶。
後端伺服器 (Backend Server):負責接收 LINE Bot 的請求,協調並調度所有的雲端 AI 服務。一旦完成所有 AI 任務,它會將整合後的數據與分析結果包裝成最終報告,再透過 LINE Bot 回傳。
資料辨識服務 (Azure Document Intelligence):這是整個流程的第一個智慧化步驟。當後端伺服器接收到用戶的營養標示圖片後,會呼叫此服務進行高精度的 OCR(光學字元辨識)與表格結構分析。這一步驟能夠準確地從複雜的食品包裝上,提取出每一份量的熱量、脂肪、鈉、糖等關鍵數據。
AI 智慧分析服務 (Gemini API):從 Document Intelligence 獲得的營養數據會被傳送至此。Gemini API 扮演了「智慧營養師」的角色,它會根據用戶先前設定的個人資訊(如性別、體重、身高)和飲食建議參考值,來分析這份食品的營養組成。它不僅會計算比例,還會生成個人化的、充滿正能量的飲食建議。
語音合成服務 (Azure TTS):為了讓報告更有溫度,後端會將 Gemini API 生成的文字報告,傳送給此語音合成服務。該服務能將文字轉化為清晰自然的語音,讓用戶能夠「聽」見分析報告,解放雙手和雙眼,使體驗更為便利。
用戶旅程細節說明
這條流程從用戶的實際情境出發,描繪了「每拍呷」如何解決他們在日常生活中遇到的困擾,並最終達成目標。
情境:在超商尋找健康零食:
用戶站在貨架前,被眼花繚亂的包裝零食所困擾。他們想做出健康的選擇,但看不懂或沒有時間去仔細研究營養標示,這是他們最主要的痛點。
第一步:拍照並上傳:
用戶啟動 LINE,對準零食包裝上的營養標示拍照並傳送。這一步驟是我們的解決方案中最簡單、也最關鍵的起點。
第二步:等待智慧分析:
當圖片傳送後,用戶只需短暫等待。此時,後端系統正在高效地進行 OCR、數據分析與個人化建議的生成。
第三步:接收報告與語音建議:
幾秒鐘後,用戶會收到 LINE Bot 傳送的完整報告。報告不僅有文字摘要,更有親切的語音解說,讓用戶能夠快速了解這份零食的營養價值,以及是否符合自己的飲食目標。
結果:做出明智的健康決策:
用戶在獲得即時且個人化的資訊後,不再需要憑感覺做決定。他們能自信地選擇適合自己的零食,如果吃了零食之後也可以聽取語音報告,下一餐做調整改善。這不僅解決了當下的困擾,也希望能幫助用戶養成長期的健康飲食習慣。
目前Flex Message介面: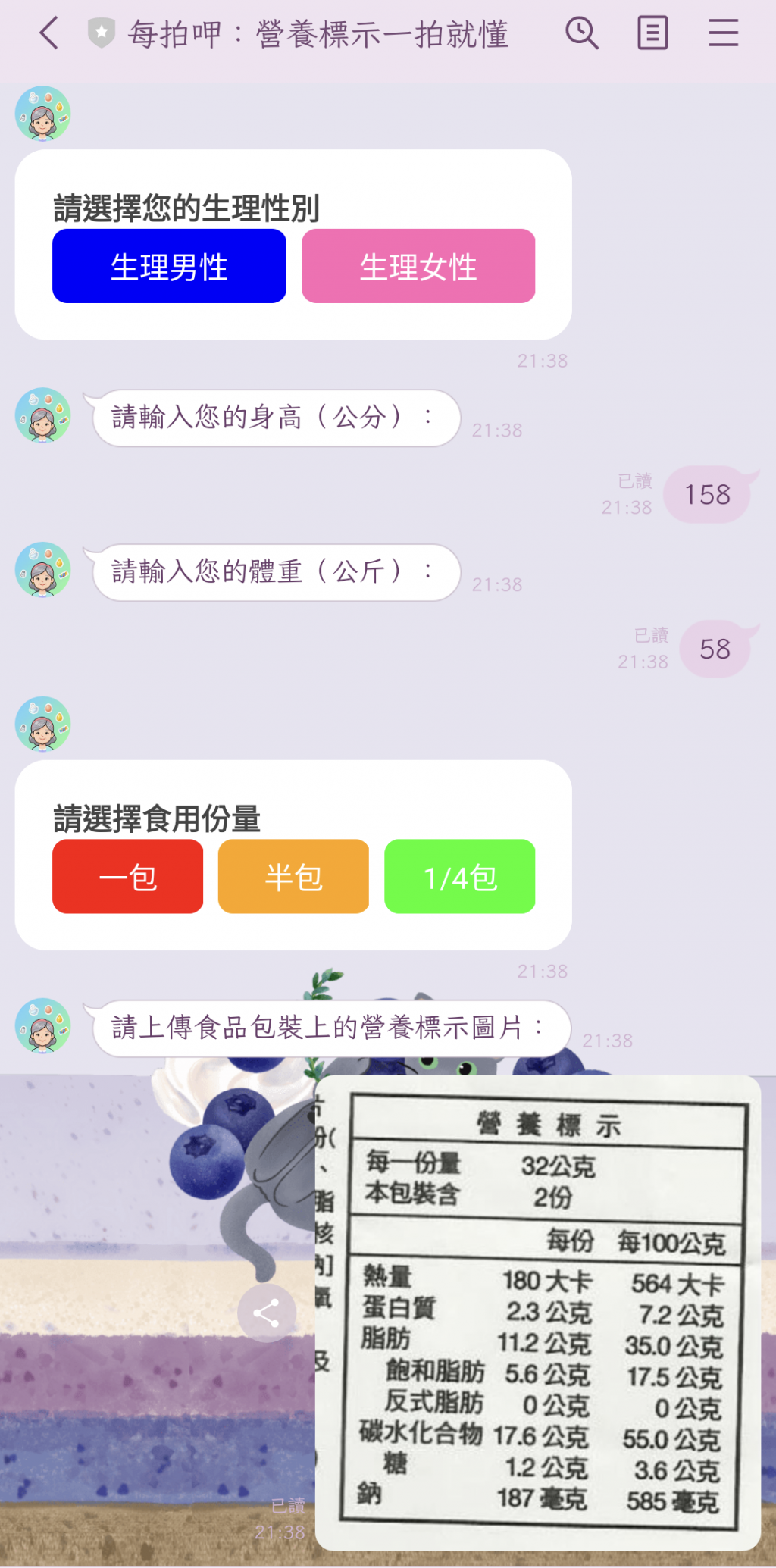
此處卡關中,希望接下來幾天可以順利解決!

